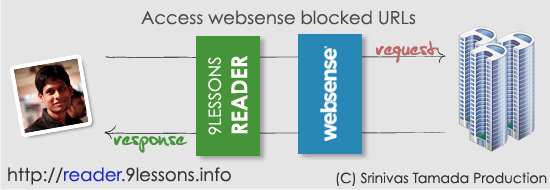
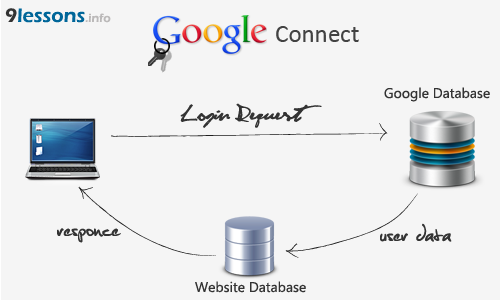
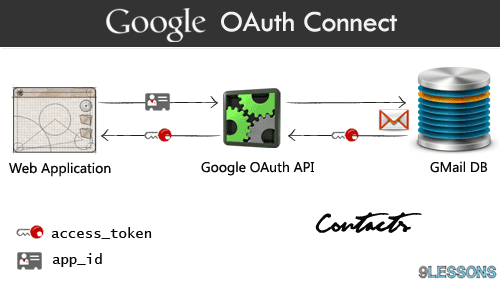
Introducing the new light weight OAuth Login commercial edition, an OAuth login system for your website with Facebook, Google, Microsoft and Linkedin. OAuth Login is very quick and powerful, sure this helps you to increase your web project registrations. It's definitely a must have login system for every PHP based web projects. Hardly it will take 10 mins for installation.